SME
Start your AI transformation.
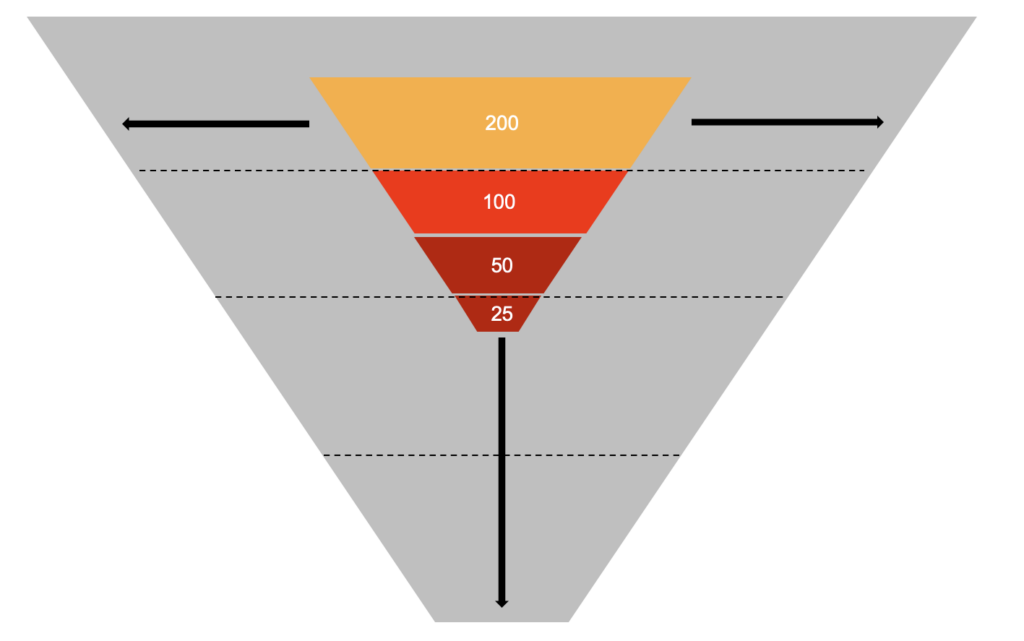
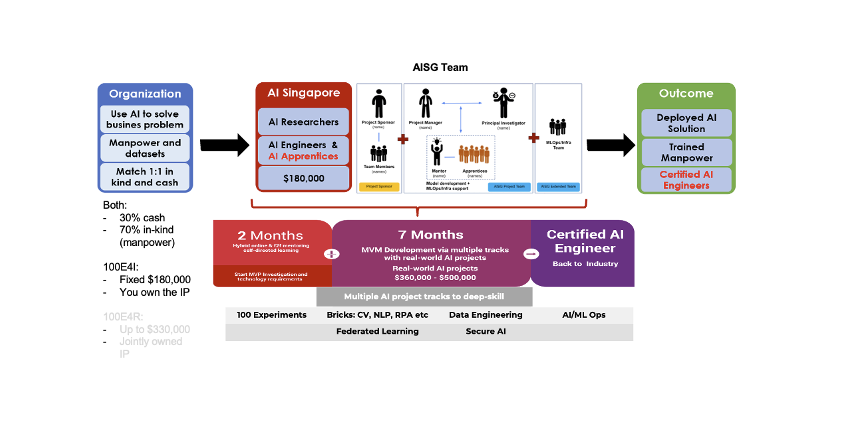
Getting started is as easy as 1-2-3-4! First understand what is AI with our popular AI For Everyone course (it is FREE!). Then take our AI Readiness Index (AIRI) assessment to better understand your organization’s AI maturity. Next find AI use cases that correlate with your business needs. And finally contact an experienced solution provider of your choice. Let’s start your AI journey today!
AI Use Cases
Discover your ideal solution. Search now.
Please note that we only log search queries for the purpose of understanding our users better and improving our services. No other information is collected.